Conversations with Documents @ CHIIR 2020
Maartje ter Hoeve, Robert Sim, Elnaz Nouri, Adam Fourney, Maarten de Rijke, Ryen White
Imagine you have a voice assistant to help you when writing a document. What would you ask?
What kinds of features would you like the voice assistant to have? And how do we actually model this?
We answer all these questions in this blog post about our CHIIR 2020 full paper!
Digital assistants have become more and more prevalent in our daily lives. We can use them to set an alarm while cooking,
to start some music for in the background and to quickly check how long the pasta needs to cook again.
Despite all this great progress, document-centered assistance -- for example to help someone to quickly
review a document -- still seems far away. In this work we aim to take some steps in the right direction. But first,
we need to answer the question: What do we actually mean by document-centered assistance?
To answer that question, we set up a survey where we asked crowd workers a number of questions. We had the possibility to
extensively train our crowd workers to do our task. Moreover, the workers were paid at an hourly rate, which removed
the incentive to rush responses. This was great and we got very high quality answers.
We presented crowd workers with the following scenario outline:
First we asked the participants whether they recognized this scenario. Good news. All but one participant answered yes to this question. Then we asked whether they would find help from a digital assistant helpful in this scenario. Again, all but one participant answered yes to this question.
This is great news. However, we still do not fully know what document-centered assistance actually entails! We came up with some interesting features and asked workers to choose which of these features they found most useful and which of these features they would find least useful. Of course, we randomized these features in order to avoid position bias. In the next table you can see all features and their abbreviations. We never showed these abbreviations to workers, but we do use them in our figures to save space. You can also see which features workers deemed most useful and which ones they did not find so useful.
| Abbreviation | Feature |
|---|---|
| cut | Cut content from the document using voice |
| dict | Dictate input to the document |
| find | Find specific text in the document using voice input |
| form | Change text formatting using voice |
| gener | Respond to general questions about the document content, using voice input and output |
| hilit | Highlight text using voice |
| ins | Insert new comments into the document using voice |
| navi | Navigate to a specific section in the document using voice input |
| paste | Paste content from the device clipboard using voice |
| read | Read out the document, or parts of it, using voice output |
| res | Respond to existing comments in the document using voice |
| rev | Revise a section of text using voice input |
| send | Send or share a section of text using voice input |
| sum | Summarize the document, or parts of it, using voice output |
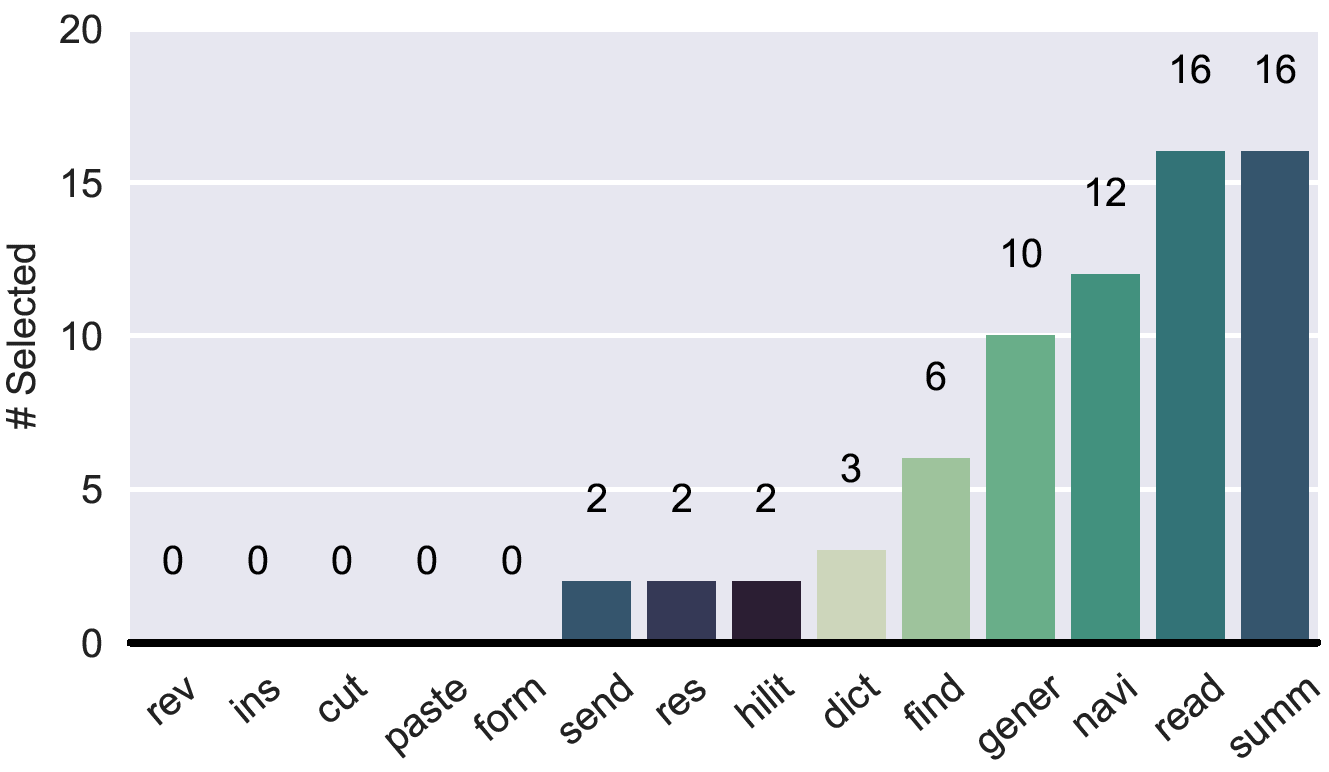
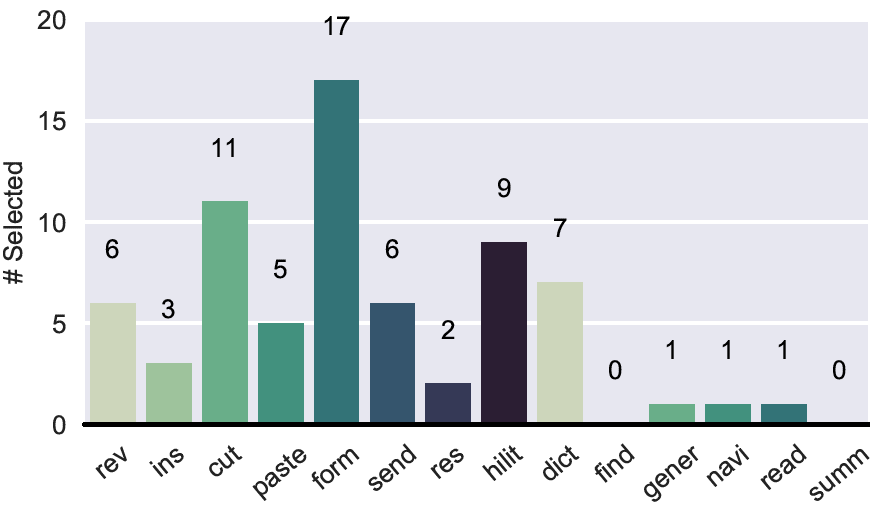
It is exciting to see that participants were very interested in having the digital assistant
read or summarize parts of the documents to them.
Navigating to parts of the document and responding to
general questions about the document were also often requested. On the other hand, a feature like
'changing the text formatting using voice' was much less popular. We think that this can be easily
explained by the nature of the scenario. Probably if you are driving to a business meeting, you care less
about the formatting of the document, whereas you do care a lot about the content.
What types of queries do participants come up with?
In the next part we simulated the outlined situation. We presented workers with an email and said that this was
the email they had received from their manager. We included a small snippet from the document in the email to make
sure that participants knew what the document was about. Then we asked them to come up with
5 questions that they
would ask to their digital assistant to help them understand what was written in the document.
We also explicitly stated that they should not feel restricted by the
(often still limited) capabilities of today's digital assistants. We did this for 20 different documents.
These documents came from a larger set and often had enterprise or corporate topics.
We ended up with 2000 questions and could categorize them according to this hierarchy:
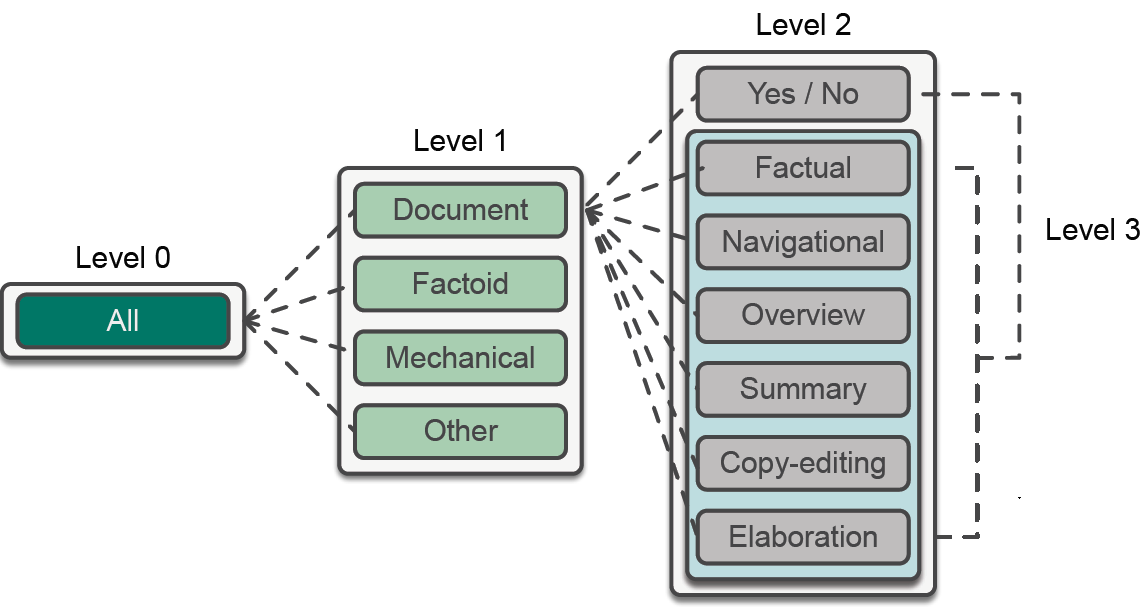
Below we explain each of these categories and give some verbatim examples of the questions we collected:
| Question Type | Description | Examples |
|---|---|---|
| Document | These are document-centered questions. That is, the question's phrasing explicitly or implicitly references the document. When asking such a question, a user is not looking for encyclopedic knowledge, but rather for assistance that can help them to author the document. These types of questions are not present in existing QA datasets. | Does the document have specifications to the type of activity and sector improvement that will be offered? |
| Factoid | Fact-oriented questions that co-owners of a document are unlikely to ask. Answers are often only a few words long. Existing QA datasets cover these types of questions very well. | What is the date of the festival? |
| Mechanical | Questions that can be answered with simple rule-based systems. | Highlight "Capability workers" |
| Other | Questions that fall outside the above categories. | Read the email to me. |
| Question Type | Description | Examples |
|---|---|---|
| Yes / No | Closed form (can be answered with 'yes' or 'no') | Does the document state who is teaching the course? |
| Factual | Questions that can be answered by returning a short statement or span extracted from the document. | Where does the document state study was done? |
| Navigational | Referring to position(s) in the document. | Go to policies and priorities in the doc. |
| Overview | Questions that refer to the aim of the document. | What is the overall focus of the article? |
| Summary | Questions that ask for a summary of the document or of a particular part of the document. | Find and summarize coaching principles in the document. |
| Copy-editing | Questions when editing a document. They require a good understanding of the document to answer. | Highlight text related to application of epidemiologic principles in the document |
| Elaboration | Questions that require complex reasoning and often involve a longer response. | Please detail the process to get access to grant funds prior to confirmation. |
We also investigated how many questions of each question type appeared in the 2000 questions. In the figures below you can see the percentages of level 1, level 2 and level 3 respectively.



So, we can see that participants asked many document-centered questions
and many closed form 'yes / no' types
of questions. The latter is the reason that we decided to split level 2 another time in level 3. We assumed
users would not just want to hear 'yes' or 'no' as an answer, but actually a bit more context.
A very important observation to make is that these document-centered questions are very different from the factoid questions.
The factoid questions are the questions that we often see in existing Question Answering (QA) datasets.
We played around with existing QA systems and time after time they failed at answering document-centered
questions. And we do not blame them! They have simply never been trained on these types of new questions.
That is why next we will collect more data so that we can train QA systems on our new document-centered questions.
Larger Data Collection, DQA
For our large scale data collection, we selected an additional 40 documents from our larger document set.
For these new documents, we collected questions in the same fashion as before. Next we collected
answers for all questions
(so also for the questions that we already collected in the survey round). Not all questions had answers in the
document. Therefore, crowd workers could also indicate that a document
did not contain an answer. This is a very
important feature of our dataset, as this situation will also occur very often in real life. We call our collected dataset
DQA, short for Document Question Answering.
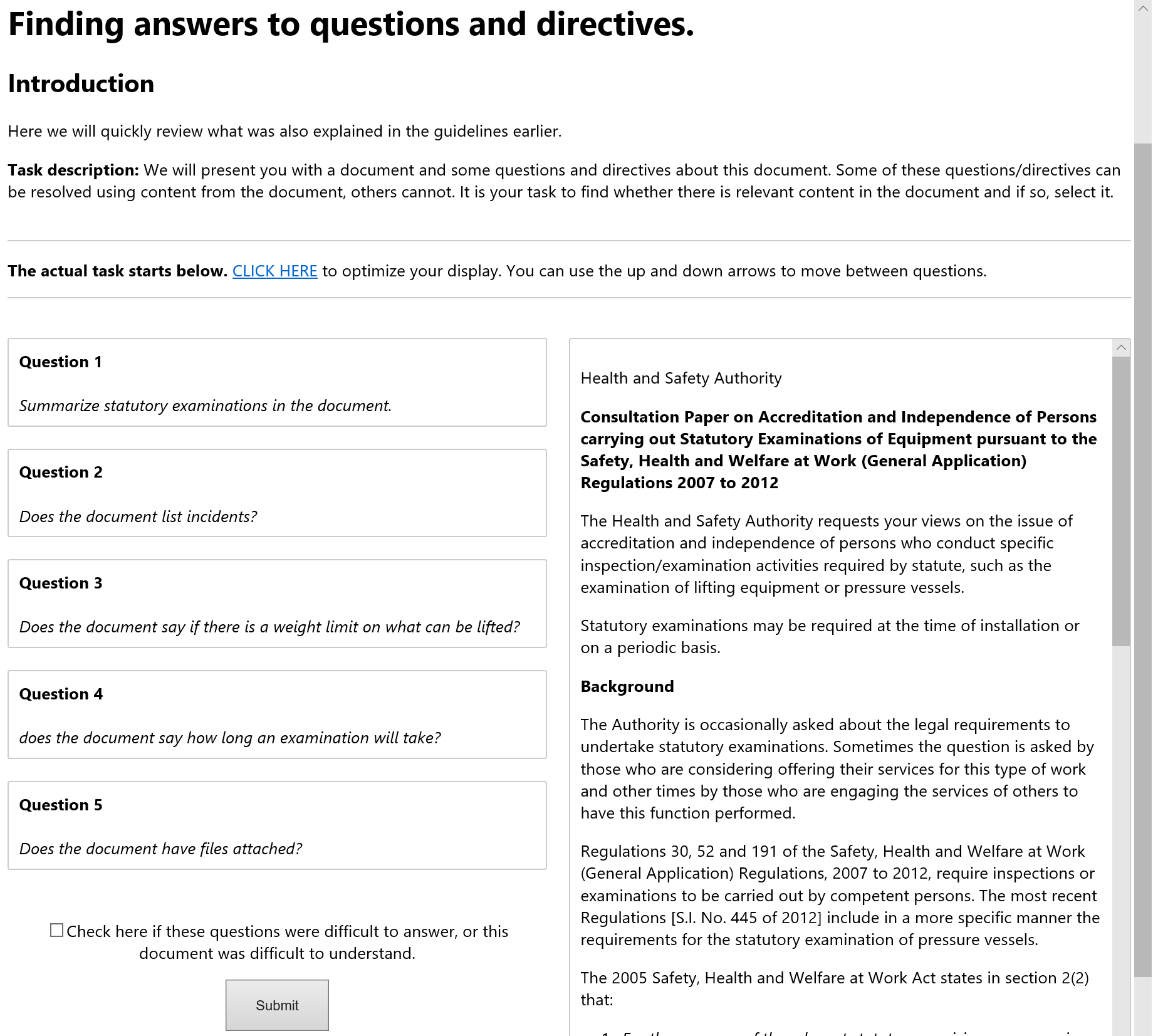
Below you can find some examples of what workers could see during this round:
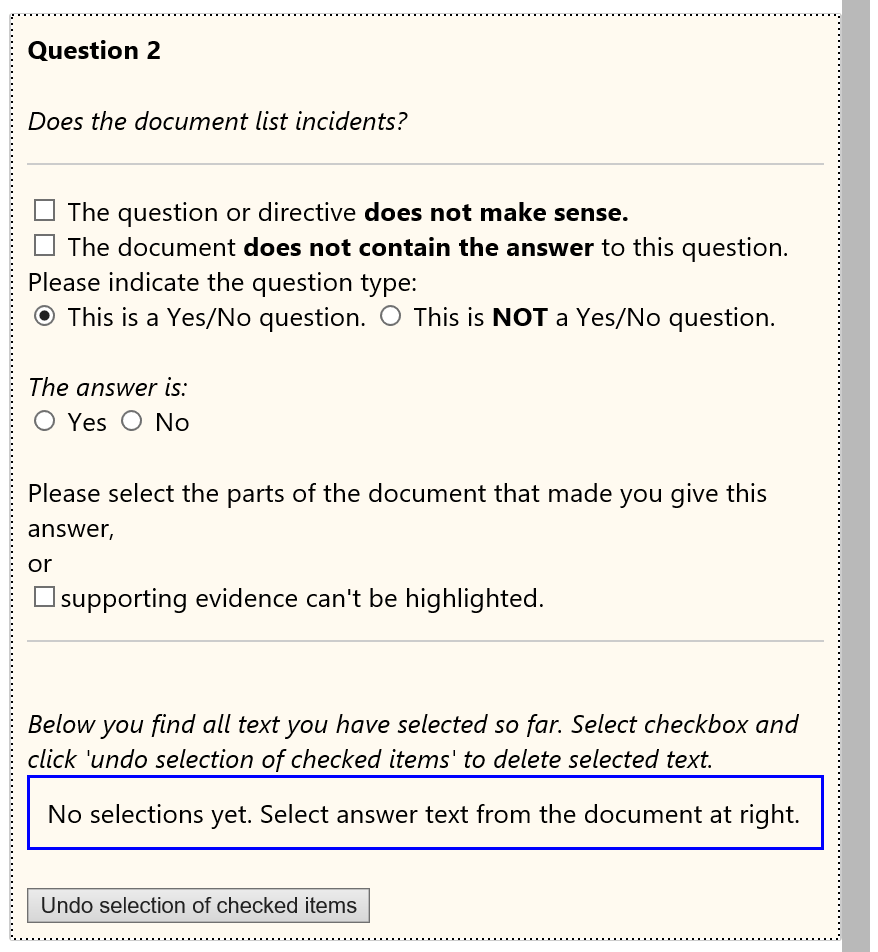
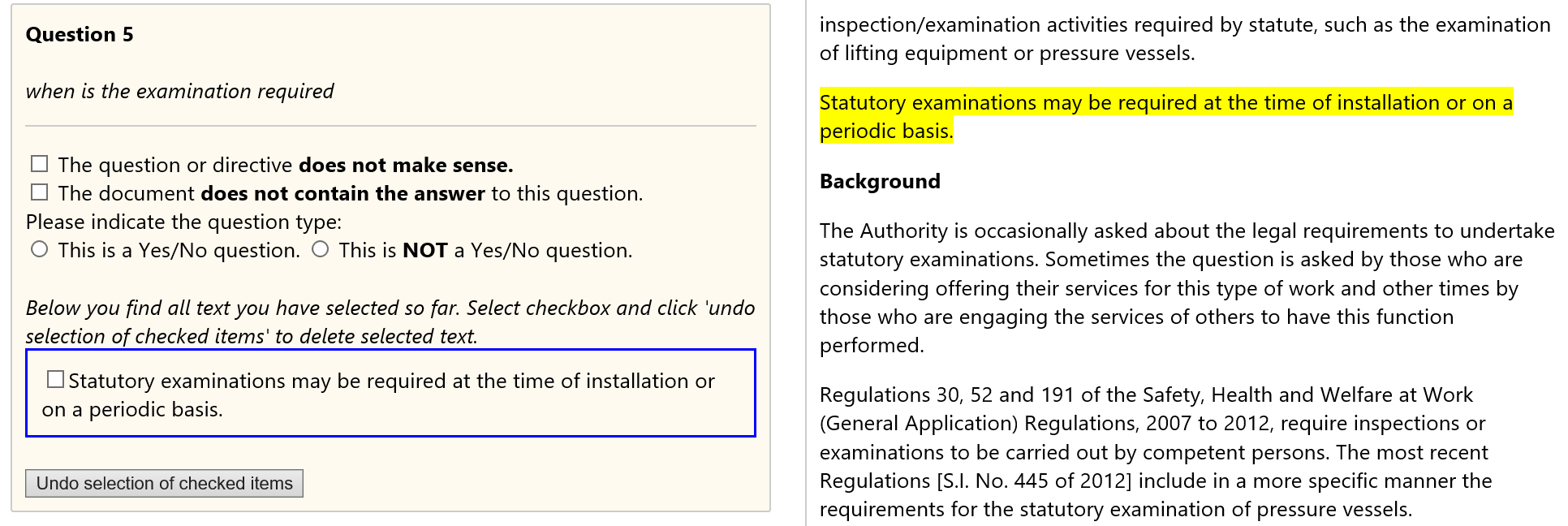
Modeling
For the modeling part we looked into passage retrieval and
answer selection. In the data collection round,
workers only selected the answers, not the passages. Therefore we used a sliding window approach to
construct passages that do contain and passages that do not contain the answers.
For the passage retrieval we made a distinction between passages that fully contain the answer and passages
that only partially contain the answers. Based on this we computed the average Precision@1. We calculated a
soft version, where points were given for returning a passage that only partially contained the answer, and
a hard version, where we only gave points for passages that contained the full answer. We also computed the Rouge-1,
Rouge-2 and Rouge-L F-scores. The scores are given in the table below.
| Model | Avg P@1 Soft | Avg P@1 Hard | Avg Rouge-1 F | Avg Rouge-2 F | Avg Rouge-L F |
|---|---|---|---|---|---|
| Random | 0.11 | 0.13 | 0.18 | 0.06 | 0.12 |
| First | 0.38 | 0.41 | 0.23 | 0.12 | 0.16 |
| BM25 | 0.21 | 0.23 | 0.21 | 0.09 | 0.15 |
We can see that always selecting the first passage gives the highest scores. This is in line with
observations from other tasks, such as summarization, where selecting the first 3 sentences of the
text often results in very descent scores.
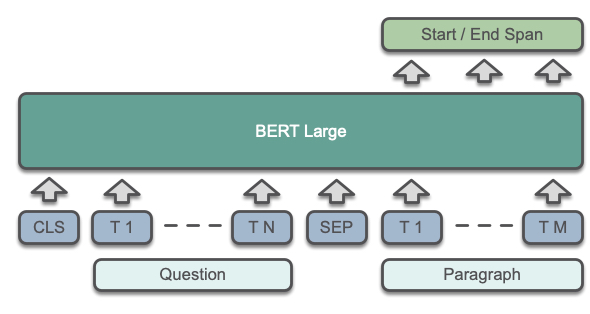
For the answer selection part we used BERT [1]. There are excellent blog posts on how BERT works, like
this one, so here we assume you are familiar with it.
In the figure below we show a high-level overview of how BERT works for Question-Answering. The question and the paragraph are
jointly fed into the BERT transformer layers. By adding one linear layer on top, the entire model is fine-tuned
to select the start and the end of the answer span.
We evaluate a couple of settings. Of course we want to see how BERT behaves when we fine-tune on our own dataset. Because our DQA dataset is not very large, we also decided to mix our data with the SQuAD2.0 dataset [2]. This is a very popular QA dataset and also contains unanswerable questions. An important difference is that the SQuAD2.0 questions are factoid questions instead of document-centered questions and that the answer spans in SQuAD2.0 are much smaller than in the DQA dataset. We also wanted to know the effect of query rewriting. For this we found the most common document related n-grams in our questions. We deleted these n-grams from the queries. The results are given in the table below. F1 and EM scores both refer to how much the model answer overlaps with the ground truth.
| Model | F1 | EM |
|---|---|---|
| Fine-tune BERT on DQA | 38.84 | 18.93 |
| Fine-tune BERT on DQA + Query Rewriting | 36.73 | 17.83 |
| Fine-tune BERT on SQuAD2.0 | 27.24 | 13.21 |
| Fine-tune BERT on SQuAD2.0 + Query Rewriting | 26.79 | 13.09 |
| Fine-tune BERT on SQuAD2.0 & DQA | 41.02 | 20.30 |
| Fine-tune BERT on SQuAD2.0 & DQA + Query Rewriting | 37.28 | 18.52 |
From these results you can see that the setting where we combined DQA with SQuAD2.0 performs best.
Query rewriting does not perform better. We think that this is because our query rewriting may have been
a bit too naive. Despite these promising results, we can also see that the scores in this table are
still very far away from the scores that you find in the SQuAD2.0 leaderboards. Very interesting observations!
We are very keen on investigating this interesting space more.
Conclusion
We have shown that users would like to receive document-centered assistance and by now we have a clear
picture of what document-centered assistance can entail. We have seen that the questions that users ask in this
domain are different from the typical factoid QA questions. State of the art QA models show promising results in the
document-centered domain, but there is still a lot to improve!
This blog post is based on our CHIIR 2020 full paper Conversations with Documents. An Exploration
of Document-Centered Assistance. You can find our paper here.
If you want to use our paper for your own work, please consider citing:
title={Conversations with Documents. An Exploration of Document-Centered Assistance},
author={ter Hoeve, Maartje and Sim, Robert and Nouri, Elnaz and Fourney, Adam and de Rijke, Maarten and White, Ryen W},
journal={arXiv preprint arXiv:2002.00747},
year={2020}
}
Bibliography
- Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics .
- Pranav Rajpurkar, Robin Jia and Percy Liang. 2018. Know what you don't know: Unanswerable questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers).